Large-scale language diffusion model(대규모 언어 확산 모델)
대규모 언어 확산 모델(Large-scale language diffusion model )
개념
'LLaDA'는 쉽게 말해, 대규모 언어 확산 모델은 인공지능이 마치 그림을 그리듯이 글을 생성하는 새로운 방식입니다. 기존의 인공지능은 글자 하나하나를 순서대로 예측하는 방식이었다면 (자기회귀 모델), 확산 모델은 먼저 흐릿한 글(노이즈)을 만들고, 이를 점진적으로 선명하게 하여 완성된 글을 만들어냅니다.
마치 뿌연 사진에 색을 입히고 디테일을 추가하여 선명한 사진을 만드는 것과 비슷합니다. 처음에는 의미 없는 잡음으로 시작하지만, 점차적으로 의미 있는 단어와 문장으로 변해가는 것이죠.
이러한 방식은 기존 방식보다 더욱 창의적이고 다양한 글을 생성할 수 있다는 장점이 있습니다. 아직 연구 초기 단계이지만, 미래에는 더욱 자연스럽고 놀라운 글쓰기 능력을 가진 인공지능을 만드는 데 중요한 역할을 할 것으로 기대됩니다. 쉽게 말해, 그림 그리는 AI처럼, 글쓰는 AI도 이런 방식으로 더욱 발전할 수 있다는 것입니다.

이 논문은 자기회귀 모델(ARM)이 대규모 언어 모델(LLM)의 기본이라는 기존의 생각에 도전합니다. 연구진은 스크래치부터 사전 훈련 및 지도 학습 미세 조정(SFT) 패러다임 하에서 훈련된 확산 모델인 LLaDA를 소개합니다. LLaDA는 순방향 데이터 마스킹 프로세스와 역방향 프로세스를 통해 분포를 모델링하며, 일반적인 변환기를 사용하여 마스크된 토큰을 예측합니다. 가능도 경계를 최적화함으로써 확률적 추론을 위한 원칙적인 생성 접근 방식을 제공합니다.
광범위한 벤치마크에서 LLaDA는 강력한 확장성을 보여주며, 자체 제작한 ARM 기준 모델을 능가합니다. 특히, LLaDA 8B는 문맥 내 학습 및 SFT 이후 다양한 지침 따르기 능력에서 강력한 LLM인 LLAMA 3 8B와 경쟁력을 갖습니다. 또한 역순 문제를 해결하여 역시 작품 완성 작업에서 GPT-40를 능가합니다.
이러한 결과는 확산 모델이 ARM에 대한 실행 가능하고 유망한 대안임을 보여주며, 기존에 LLM의 핵심 기능으로 여겨졌던 것들이 ARM에 본질적으로 의존한다는 가정에 도전합니다.
관련 추가지식
"대규모 언어 확산 모델(Large Language Diffusion Models)"이라는 제목의 연구 논문의 일부입니다. 이 논문은 기존의 자기회귀 모델(Autoregressive Models, ARM) 기반 대규모 언어 모델(LLM)에 대한 새로운 접근 방식을 제시합니다. 구체적으로, **확산 모델(Diffusion Model)**을 이용하여 LLM을 훈련하는 방법을 제안하고, 그 결과를 기존의 ARM 기반 LLM과 비교 분석합니다.
이미지에서 볼 수 있는 주요 내용은 다음과 같습니다.
- LLaDA 모델 소개: 논문에서 새롭게 제안하는 LLaDA라는 확산 모델이 소개됩니다. LLaDA는 기존의 자기회귀 모델과 달리, 데이터에 노이즈를 추가하고 역으로 노이즈를 제거하는 과정을 통해 텍스트를 생성합니다. 이러한 과정은 순방향 데이터 마스킹(forward data masking)과 역방향 프로세스(reverse process)로 설명됩니다.
- 벤치마크 결과: 그림 1은 LLaDA 모델의 성능을 다양한 벤치마크(Zero/Few-Shot Benchmarks)에서 기존의 강력한 LLM (LLAMA 3 8B, LLAMA 2 7B 등)과 비교한 결과를 보여줍니다. 결과는 LLaDA가 경쟁력 있는 성능을 보임을 시사합니다. 특히, 문맥 내 학습(in-context learning) 및 지시 사항 따르기(instruction-following) 능력에서 좋은 결과를 나타냅니다.
- 자기회귀 모델에 대한 도전: 논문은 자기회귀 모델(ARM)이 LLM의 필수적인 요소라는 기존의 통념에 도전합니다. 확산 모델 기반의 LLaDA가 ARM 기반 모델과 비교하여 경쟁력 있는 성능을 보임으로써, LLM 개발에 있어서 ARM 이외의 다른 접근 방식도 가능함을 보여주려는 의도를 가지고 있습니다.
- 수식: 이미지에는 확산 모델의 핵심적인 수식(1)과 (2)가 포함되어 있습니다. 수식 (1)은 모델 분포의 최적화를 위한 최대 가능도 추정 또는 KL 발산 최소화를 나타내고, 수식 (2)는 자기회귀 모델의 확률 분포를 정의하는 표현입니다.
요약하자면, 이 이미지는 확산 모델을 이용한 새로운 LLM인 LLaDA를 소개하고, 기존의 자기회귀 모델 기반 LLM과 비교하여 그 성능과 가능성을 보여주는 연구 논문의 일부입니다. 이 연구는 LLM 개발에 대한 새로운 관점을 제시하고, ARM에 대한 의존성을 낮추는 대안을 제시하는 데 의의가 있습니다.
"순방향 데이터 마스킹"은 무엇을 의미하나요?
**순방향 데이터 마스킹(Forward Data Masking)**은 특정 데이터의 일부를 의도적으로 가리고(masking) 나머지 정보만을 이용하여 모델을 훈련시키는 기법입니다. 이는 주로 생성 모델(Generative Model), 특히 **확산 모델(Diffusion Model)**에서 사용됩니다.
순방향 데이터 마스킹의 과정은 다음과 같습니다.
1. 데이터에 노이즈 추가: 처음에는 원본 데이터에 점진적으로 노이즈(잡음)를 추가합니다. 이 노이즈는 데이터의 일부를 흐릿하게 하거나, 일부 정보를 랜덤하게 변경하는 형태를 띱니다. 노이즈의 양은 단계적으로 증가합니다.
2. 마스킹: 노이즈가 추가된 데이터에서 특정 부분을 가립니다. 이 "가림"이 바로 마스킹입니다. 가리는 부분은 임의적일 수도 있고, 특정 패턴을 따라 가릴 수도 있습니다.
3. 모델 훈련: 마스킹된 데이터를 모델에 입력으로 제공하고, 모델은 가려진 부분을 예측하도록 훈련됩니다. 즉, 모델은 노이즈가 추가된 불완전한 데이터에서 원본 데이터를 복원하는 것을 학습합니다.
4. 역방향 프로세스: 훈련된 모델은 이제 새로운 데이터에 노이즈를 추가하고, 역방향으로 노이즈를 제거하여 새로운 데이터를 생성하는 데 사용됩니다. 이 역방향 프로세스는 순방향 마스킹 과정의 반대 과정입니다.
순방향 데이터 마스킹의 목적:
- 과적합 방지: 데이터의 일부를 가림으로써 모델이 특정 데이터에 과하게 의존하는 것을 방지합니다. 더 일반적인 패턴을 학습하도록 유도합니다.
- 생성 능력 향상: 불완전한 정보로부터 원본 데이터를 복원하는 과정을 통해 모델의 생성 능력을 향상시킵니다. 새로운 데이터를 생성할 때 더욱 창의적이고 다양한 결과를 만들어낼 수 있습니다.
- 데이터 프라이버시 보호: 민감한 정보를 포함하는 데이터에서 특정 부분을 가려 데이터 프라이버시를 보호할 수 있습니다.
결론적으로, 순방향 데이터 마스킹은 모델의 학습 과정에 의도적으로 불확실성을 도입하여 모델의 일반화 능력과 생성 능력을 향상시키는 중요한 기법입니다. 특히 LLaDA와 같은 확산 모델에서 중요한 역할을 합니다.
어떤 종류의 노이즈가 사용되나요?
LLaDA 논문이나 일반적인 확산 모델에서 사용되는 노이즈의 종류는 명확하게 특정 알고리즘으로 한정짓기 어렵습니다. 그러나 일반적으로 사용되는 노이즈 추가 방법은 **가우시안 노이즈(Gaussian Noise)**를 기반으로 합니다. 하지만 단순히 가우시안 노이즈만을 사용하는 것이 아니라, 다양한 변형이나 조합을 통해 더욱 효과적인 노이즈 추가 방식을 사용할 수 있습니다.
구체적으로 어떤 종류의 노이즈가 사용되었는지는 논문의 세부적인 구현 부분을 확인해야 알 수 있습니다. 논문에 명시적으로 언급되지 않았다면, 연구자들이 다양한 노이즈 추가 방법들을 실험하고 가장 좋은 성능을 내는 방법을 선택했을 가능성이 높습니다.
가우시안 노이즈 외에 고려될 수 있는 다른 노이즈 종류들은 다음과 같습니다:
- 솔트 앤 페퍼 노이즈(Salt and Pepper Noise): 이미지 처리에서 흔히 사용되는 노이즈로, 이미지의 픽셀 값을 임의로 최대값 또는 최소값으로 바꿉니다. 텍스트 데이터에도 적용할 수 있지만, 문맥을 고려한 변형이 필요할 것입니다. (예: 특정 토큰을 임의로 다른 토큰으로 바꾸는 등)
- 균일 노이즈(Uniform Noise): 특정 범위 내에서 균일하게 분포된 랜덤 값을 추가하는 노이즈입니다. 가우시안 노이즈보다 단순하지만, 특정 상황에서는 효과적일 수 있습니다.
- 첨가형 노이즈(Additive Noise): 원본 데이터에 다른 랜덤 데이터를 직접 더하는 방식입니다. 가우시안 노이즈가 이에 해당합니다.
- 곱셈형 노이즈(Multiplicative Noise): 원본 데이터에 랜덤 값을 곱하는 방식입니다.
- 다양한 노이즈의 조합: 실제로는 위에 언급된 여러 종류의 노이즈를 조합하여 사용할 수 있습니다. 예를 들어, 가우시안 노이즈와 솔트 앤 페퍼 노이즈를 결합하여 더욱 다양한 형태의 노이즈를 생성할 수 있습니다.
중요한 점은 노이즈의 종류뿐만 아니라 **노이즈의 강도(intensity)와 추가 방식(scheduling)**도 모델의 성능에 큰 영향을 미친다는 것입니다. 논문에서는 이러한 요소들을 어떻게 조정했는지 자세히 설명하고 있을 가능성이 높습니다. 따라서 논문의 구현 세부 사항을 확인하는 것이 가장 정확한 답변을 얻는 방법입니다.
노이즈 추가 방법의 예시가 있을까요?

확산 모델에서 사용되는 노이즈 추가 방법은 다양하지만, 대부분 **가우시안 노이즈(Gaussian noise)**를 기반으로 합니다. 가우시안 노이즈는 평균이 0이고 표준편차가 특정 값인 정규 분포를 따르는 랜덤 값입니다. 이 노이즈를 데이터에 추가하는 방법은 여러 가지가 있습니다. 몇 가지 예시를 들어 설명하겠습니다.
1. 가우시안 노이즈의 직접적인 추가:이 논문은 자기회귀 모델(ARM)이 대규모 언어 모델(LLM)의 기본이라는 기존의 생각에 도전합니다. 연구진은 스크래치부터 사전 훈련 및 지도 학습 미세 조정(SFT) 패러다임 하에서 훈련된 확산 모델인 LLaDA를 소개합니다. LLaDA는 순방향 데이터 마스킹 프로세스와 역방향 프로세스를 통해 분포를 모델링하며, 일반적인 변환기를 사용하여 마스크된 토큰을 예측합니다. 가능도 경계를 최적화함으로써 확률적 추론을 위한 원칙적인 생성 접근 방식을 제공합니다.
광범위한 벤치마크에서 LLaDA는 강력한 확장성을 보여주며, 자체 제작한 ARM 기준 모델을 능가합니다. 특히, LLaDA 8B는 문맥 내 학습 및 SFT 이후 다양한 지침 따르기 능력에서 강력한 LLM인 LLAMA 3 8B와 경쟁력을 갖습니다. 또한 역순 문제를 해결하여 역시 작품 완성 작업에서 GPT-40를 능가합니다.
이러한 결과는 확산 모델이 ARM에 대한 실행 가능하고 유망한 대안임을 보여주며, 기존에 LLM의 핵심 기능으로 여겨졌던 것들이 ARM에 본질적으로 의존한다는 가정에 도전합니다.
관련 추가지식
"대규모 언어 확산 모델(Large Language Diffusion Models)"이라는 제목의 연구 논문의 일부입니다. 이 논문은 기존의 자기회귀 모델(Autoregressive Models, ARM) 기반 대규모 언어 모델(LLM)에 대한 새로운 접근 방식을 제시합니다. 구체적으로, **확산 모델(Diffusion Model)**을 이용하여 LLM을 훈련하는 방법을 제안하고, 그 결과를 기존의 ARM 기반 LLM과 비교 분석합니다.
이미지에서 볼 수 있는 주요 내용은 다음과 같습니다.
- LLaDA 모델 소개: 논문에서 새롭게 제안하는 LLaDA라는 확산 모델이 소개됩니다. LLaDA는 기존의 자기회귀 모델과 달리, 데이터에 노이즈를 추가하고 역으로 노이즈를 제거하는 과정을 통해 텍스트를 생성합니다. 이러한 과정은 순방향 데이터 마스킹(forward data masking)과 역방향 프로세스(reverse process)로 설명됩니다.
- 벤치마크 결과: 그림 1은 LLaDA 모델의 성능을 다양한 벤치마크(Zero/Few-Shot Benchmarks)에서 기존의 강력한 LLM (LLAMA 3 8B, LLAMA 2 7B 등)과 비교한 결과를 보여줍니다. 결과는 LLaDA가 경쟁력 있는 성능을 보임을 시사합니다. 특히, 문맥 내 학습(in-context learning) 및 지시 사항 따르기(instruction-following) 능력에서 좋은 결과를 나타냅니다.
- 자기회귀 모델에 대한 도전: 논문은 자기회귀 모델(ARM)이 LLM의 필수적인 요소라는 기존의 통념에 도전합니다. 확산 모델 기반의 LLaDA가 ARM 기반 모델과 비교하여 경쟁력 있는 성능을 보임으로써, LLM 개발에 있어서 ARM 이외의 다른 접근 방식도 가능함을 보여주려는 의도를 가지고 있습니다.
- 수식: 이미지에는 확산 모델의 핵심적인 수식(1)과 (2)가 포함되어 있습니다. 수식 (1)은 모델 분포의 최적화를 위한 최대 가능도 추정 또는 KL 발산 최소화를 나타내고, 수식 (2)는 자기회귀 모델의 확률 분포를 정의하는 표현입니다.
요약하자면, 이 이미지는 확산 모델을 이용한 새로운 LLM인 LLaDA를 소개하고, 기존의 자기회귀 모델 기반 LLM과 비교하여 그 성능과 가능성을 보여주는 연구 논문의 일부입니다. 이 연구는 LLM 개발에 대한 새로운 관점을 제시하고, ARM에 대한 의존성을 낮추는 대안을 제시하는 데 의의가 있습니다.
"순방향 데이터 마스킹"은 무엇을 의미하나요?
**순방향 데이터 마스킹(Forward Data Masking)**은 특정 데이터의 일부를 의도적으로 가리고(masking) 나머지 정보만을 이용하여 모델을 훈련시키는 기법입니다. 이는 주로 생성 모델(Generative Model), 특히 **확산 모델(Diffusion Model)**에서 사용됩니다.
순방향 데이터 마스킹의 과정은 다음과 같습니다.
1. 데이터에 노이즈 추가: 처음에는 원본 데이터에 점진적으로 노이즈(잡음)를 추가합니다. 이 노이즈는 데이터의 일부를 흐릿하게 하거나, 일부 정보를 랜덤하게 변경하는 형태를 띱니다. 노이즈의 양은 단계적으로 증가합니다.
2. 마스킹: 노이즈가 추가된 데이터에서 특정 부분을 가립니다. 이 "가림"이 바로 마스킹입니다. 가리는 부분은 임의적일 수도 있고, 특정 패턴을 따라 가릴 수도 있습니다.
3. 모델 훈련: 마스킹된 데이터를 모델에 입력으로 제공하고, 모델은 가려진 부분을 예측하도록 훈련됩니다. 즉, 모델은 노이즈가 추가된 불완전한 데이터에서 원본 데이터를 복원하는 것을 학습합니다.
4. 역방향 프로세스: 훈련된 모델은 이제 새로운 데이터에 노이즈를 추가하고, 역방향으로 노이즈를 제거하여 새로운 데이터를 생성하는 데 사용됩니다. 이 역방향 프로세스는 순방향 마스킹 과정의 반대 과정입니다.
순방향 데이터 마스킹의 목적:
- 과적합 방지: 데이터의 일부를 가림으로써 모델이 특정 데이터에 과하게 의존하는 것을 방지합니다. 더 일반적인 패턴을 학습하도록 유도합니다.
- 생성 능력 향상: 불완전한 정보로부터 원본 데이터를 복원하는 과정을 통해 모델의 생성 능력을 향상시킵니다. 새로운 데이터를 생성할 때 더욱 창의적이고 다양한 결과를 만들어낼 수 있습니다.
- 데이터 프라이버시 보호: 민감한 정보를 포함하는 데이터에서 특정 부분을 가려 데이터 프라이버시를 보호할 수 있습니다.
결론적으로, 순방향 데이터 마스킹은 모델의 학습 과정에 의도적으로 불확실성을 도입하여 모델의 일반화 능력과 생성 능력을 향상시키는 중요한 기법입니다. 특히 LLaDA와 같은 확산 모델에서 중요한 역할을 합니다.
어떤 종류의 노이즈가 사용되나요?
LLaDA 논문이나 일반적인 확산 모델에서 사용되는 노이즈의 종류는 명확하게 특정 알고리즘으로 한정짓기 어렵습니다. 그러나 일반적으로 사용되는 노이즈 추가 방법은 **가우시안 노이즈(Gaussian Noise)**를 기반으로 합니다. 하지만 단순히 가우시안 노이즈만을 사용하는 것이 아니라, 다양한 변형이나 조합을 통해 더욱 효과적인 노이즈 추가 방식을 사용할 수 있습니다.
구체적으로 어떤 종류의 노이즈가 사용되었는지는 논문의 세부적인 구현 부분을 확인해야 알 수 있습니다. 논문에 명시적으로 언급되지 않았다면, 연구자들이 다양한 노이즈 추가 방법들을 실험하고 가장 좋은 성능을 내는 방법을 선택했을 가능성이 높습니다.
가우시안 노이즈 외에 고려될 수 있는 다른 노이즈 종류들은 다음과 같습니다:
- 솔트 앤 페퍼 노이즈(Salt and Pepper Noise): 이미지 처리에서 흔히 사용되는 노이즈로, 이미지의 픽셀 값을 임의로 최대값 또는 최소값으로 바꿉니다. 텍스트 데이터에도 적용할 수 있지만, 문맥을 고려한 변형이 필요할 것입니다. (예: 특정 토큰을 임의로 다른 토큰으로 바꾸는 등)
- 균일 노이즈(Uniform Noise): 특정 범위 내에서 균일하게 분포된 랜덤 값을 추가하는 노이즈입니다. 가우시안 노이즈보다 단순하지만, 특정 상황에서는 효과적일 수 있습니다.
- 첨가형 노이즈(Additive Noise): 원본 데이터에 다른 랜덤 데이터를 직접 더하는 방식입니다. 가우시안 노이즈가 이에 해당합니다.
- 곱셈형 노이즈(Multiplicative Noise): 원본 데이터에 랜덤 값을 곱하는 방식입니다.
- 다양한 노이즈의 조합: 실제로는 위에 언급된 여러 종류의 노이즈를 조합하여 사용할 수 있습니다. 예를 들어, 가우시안 노이즈와 솔트 앤 페퍼 노이즈를 결합하여 더욱 다양한 형태의 노이즈를 생성할 수 있습니다.
중요한 점은 노이즈의 종류뿐만 아니라 **노이즈의 강도(intensity)와 추가 방식(scheduling)**도 모델의 성능에 큰 영향을 미친다는 것입니다. 논문에서는 이러한 요소들을 어떻게 조정했는지 자세히 설명하고 있을 가능성이 높습니다. 따라서 논문의 구현 세부 사항을 확인하는 것이 가장 정확한 답변을 얻는 방법입니다.
노이즈 추가 방법의 예시가 있을까요?
가장 간단한 방법은 원본 데이터에 직접 가우시안 노이즈를 더하는 것입니다. 예를 들어, 이미지 데이터라면 각 픽셀의 값에 가우시안 노이즈를 더하고, 텍스트 데이터라면 각 토큰의 임베딩 벡터에 가우시안 노이즈를 더할 수 있습니다. 이때, 노이즈의 강도(표준편차)는 중요한 매개변수이며, 학습 단계에 따라 조절될 수 있습니다. 일반적으로 학습 초반에는 노이즈의 강도가 크고, 학습 후반으로 갈수록 노이즈의 강도가 작아지는 스케줄링(scheduling) 기법이 사용됩니다.
수식적 표현:
x_noisy = x + N(0, σ)
여기서 x 는 원본 데이터, x_noisy 는 노이즈가 추가된 데이터, N(0, σ) 는 평균이 0이고 표준편차가 σ 인 가우시안 노이즈입니다. σ 는 노이즈의 강도를 제어하는 하이퍼파라미터입니다.
2. 마스킹(Masking):
데이터의 일부를 임의로 선택하여 가리는 방법입니다. 이미지 데이터라면 픽셀을, 텍스트 데이터라면 토큰을 가릴 수 있습니다. 가려진 부분은 노이즈로 간주할 수 있으며, 모델은 가려진 부분을 예측하도록 학습됩니다. 마스킹은 노이즈 추가의 한 형태로 볼 수 있으며, 특히 텍스트 데이터에 효과적입니다.
3. 첨가형 노이즈와 곱셈형 노이즈:
데이터에 노이즈를 더하는 방식(첨가형) 외에도, 데이터에 노이즈를 곱하는 방식(곱셈형)도 사용될 수 있습니다. 이 경우, 노이즈의 강도는 곱셈 계수로 조절됩니다.
4. 다른 노이즈 분포:
가우시안 노이즈 외에도, 다른 종류의 노이즈 분포를 사용할 수 있습니다. 예를 들어, 균일 분포(Uniform distribution)를 따르는 노이즈를 사용할 수도 있습니다. 하지만 가우시안 노이즈가 가장 널리 사용되는 이유는 수학적으로 다루기 쉽고, 다양한 상황에서 좋은 성능을 보이기 때문입니다.
위에 제시된 방법들은 단순한 예시이며, 실제로는 더욱 복잡하고 정교한 노이즈 추가 방법들이 사용될 수 있습니다. 특정 확산 모델에서 어떤 노이즈 추가 방법을 사용하는지는 모델의 구체적인 구현 방식에 따라 달라집니다. LLaDA의 경우 논문을 참고해야 정확한 방법을 알 수 있습니다.
여기서 사용된수식에 대해서 설명해주세요.
이미지에 제시된 수식은 확산 모델의 핵심 원리를 나타내는 수식입니다. 두 개의 수식이 있는데, 각각 다른 의미를 지닙니다.
수식 (1): 최대 가능도 추정 또는 KL 발산 최소화
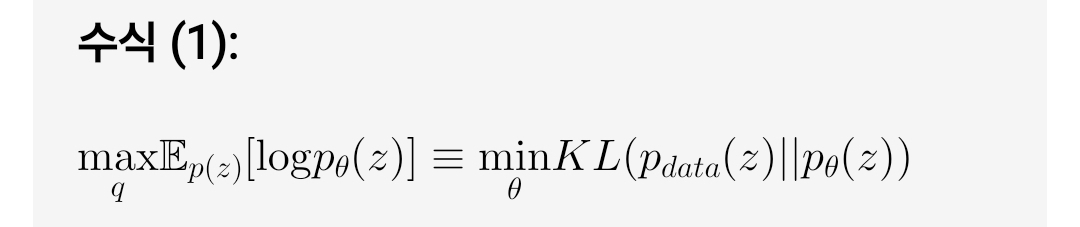
max<sub>q</sub> E<sub>p(z)</sub>[log p<sub>θ</sub>(z)] ≡ min<sub>θ</sub> KL(p<sub>data</sub>(z)||p<sub>θ</sub>(z))
이 수식은 확산 모델이 데이터 분포를 얼마나 잘 학습했는지를 측정하는 방법을 나타냅니다.
- p<sub>data</sub>(z) : 실제 데이터의 분포. 즉, 모델이 학습해야 하는 목표 분포입니다.
- p<sub>θ</sub>(z) : 모델이 학습을 통해 생성한 데이터의 분포. θ는 모델의 파라미터를 나타냅니다.
- KL(p<sub>data</sub>(z)||p<sub>θ</sub>(z)) : KL 발산(Kullback-Leibler divergence). 두 확률 분포 사이의 차이를 측정하는 지표입니다. KL 발산이 0에 가까울수록 두 분포가 유사하다는 것을 의미합니다. 즉, 모델이 실제 데이터 분포를 잘 학습했다는 것을 의미합니다.
- E<sub>p(z)</sub>[log p<sub>θ</sub>(z)] : 로그 가능도(log-likelihood). 모델이 실제 데이터를 얼마나 잘 생성할 수 있는지를 나타내는 지표입니다. 로그 가능도가 클수록 모델이 데이터를 잘 생성한다는 것을 의미합니다.
수식 (1)은 KL 발산을 최소화하는 것이 로그 가능도를 최대화하는 것과 동일하다는 것을 보여줍니다. 즉, 모델은 KL 발산을 최소화하거나, 로그 가능도를 최대화함으로써 실제 데이터 분포를 잘 학습할 수 있습니다. 이는 확산 모델의 훈련 목표를 수식으로 표현한 것입니다.
수식 (2): 자기회귀 모델의 확률 분포
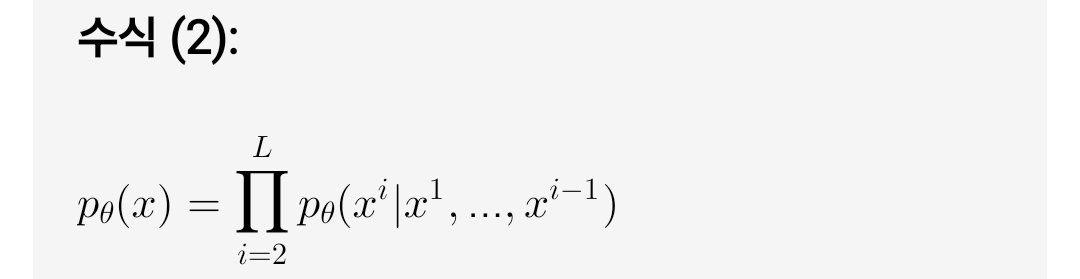
p<sub>θ</sub>(x) = Π<sup>L</sup><sub>i=2</sub> p<sub>θ</sub>(x<sup>i</sup>|x<sup>1</sup>,...,x<sup>i-1</sup>)
This equation represents the probability distribution of the Autoregressive Model. The autoregressive model is a model that predicts the next token based on previous tokens.
- x: Sequences of length L (e.g. sentences).
- x<sup>i</sup>: the i-th token of sequence x.
- p<sub>θ</sub>(x<sup>i</sup>|x<sup>1</sup>,...,x<sup>i-1</sup>): The probability that the i-th token xi occurs when given previous tokens x1,...,xi-1. θ is a parameter of the model.
Equation (2) represents the probability of the entire sequence x as the product of the conditional probabilities of each token. In other words, the autoregressive model uses the information from previous tokens to predict the probability of the next token, thereby generating a full sequence. This formula appears to have been presented in the LLaDA paper to compare and contrast with the existing autoregressive model method. Since LLaDA is a diffusion model rather than an autoregressive model, this equation does not describe the way LLaDA itself operates, but rather represents the way the autoregressive model operates as a comparison.
In summary, Equation (1) represents the training goal of a diffusion model such as LLaDA, and Equation (2) represents the stochastic generation process of an autoregressive model to be compared. The two formulas are contrasting examples of different models' approaches.
Note:
Here is the equation in the form of a mathematical formula, expressed in rows. I used LaTeX format. If the rendering is not correct, you need a LaTeX-supporting renderer.
Equation (1):
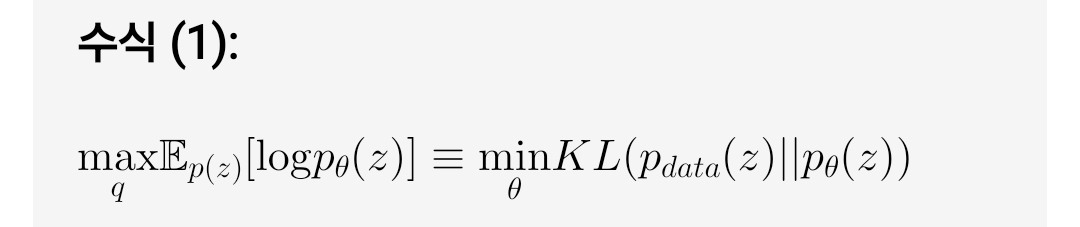
\max\limits_{q} \mathbb{E}_{p(z)}[\log p_{\theta}(z)] \equiv \min\limits_{\theta} KL(p_{data}(z) || p_{\theta}(z))
Equation (2):
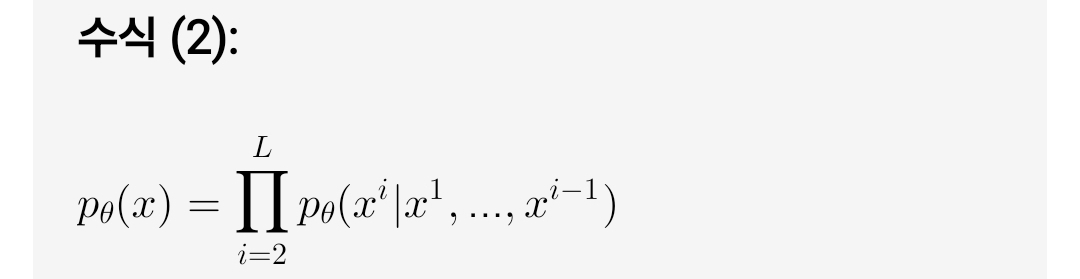
p_{\theta}(x) = \prod_{i=2}^{L} p_{\theta}(x^{i}|x^{1},...,x^{i-1})
This representation is more mathematically clear. In particular, the maximization and minimization operators (\max, \min) and the expectation operator (\mathbb{E}) are clearly displayed. KL divergence is expressed explicitly as KL(p_{data}(z) || p_{\theta}(z)) to show the difference between two distributions. In addition, the probability distribution of the autoregressive model is explicitly expressed by using the multiplication operator (\prod).
Source: Bridge of Love and Compassion